Twitterから離れるにあたり念の為データをバックアップしました。(方法)せっかく過去の全てのツイートのデータを取得できたのでCode Interpreterに入れてどんな人物か推定させてみました。
面白半分に分析を始めましたが思ってた以上に推測されてだんだん怖くなっていったという記録です。
読み込み

もうこれぐらいでは驚きませんがアップロードしたら余分な行を削除してJSONだけを取り出して読み込みました。
分析内容を提案してもらう
 分析内容を考えるなんて人間のすることではありません。考えてもらいます。
分析内容を考えるなんて人間のすることではありません。考えてもらいます。
年別の時間帯別の投稿数
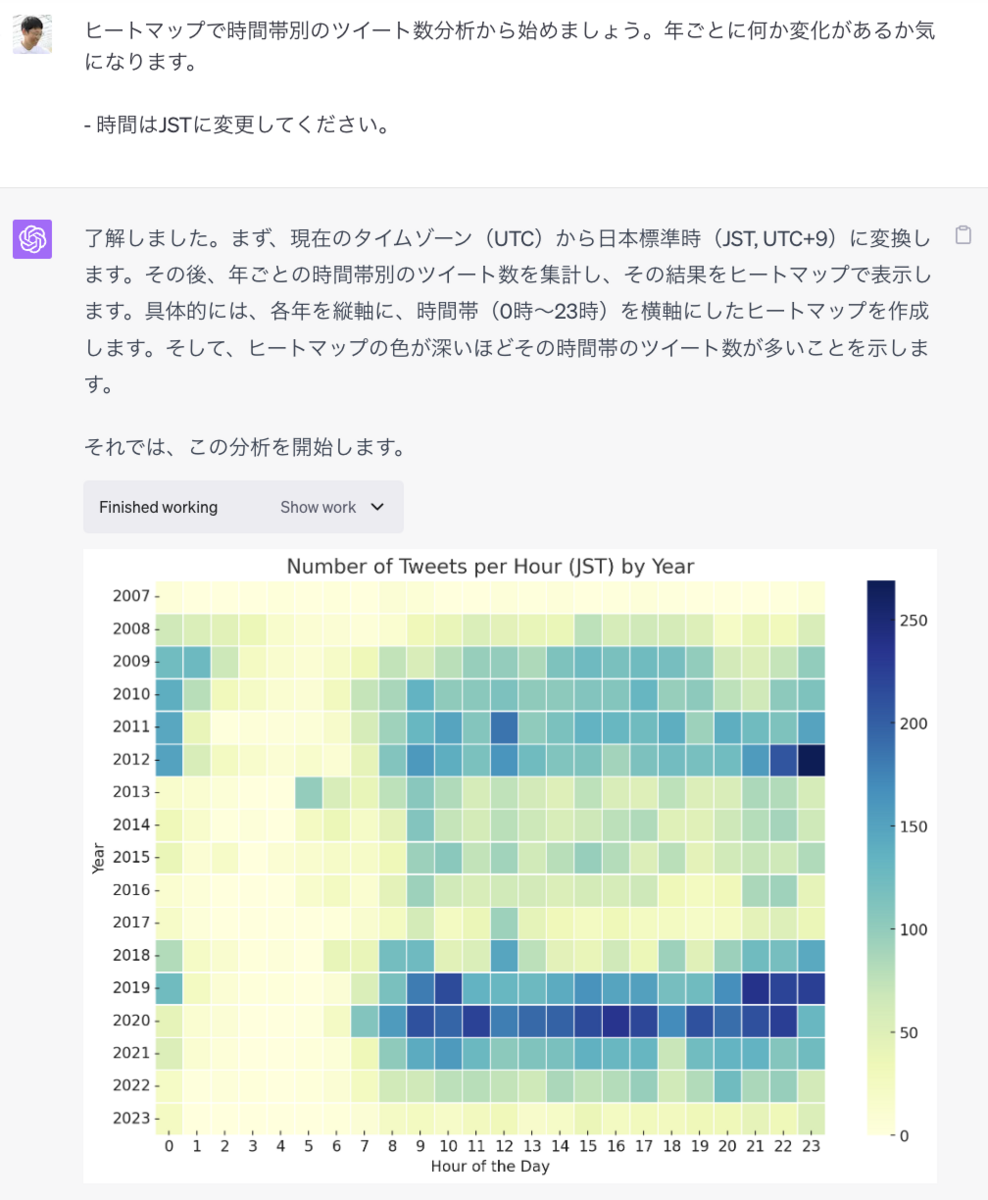
2013年に起業したのでツイートが減り、2019年に会社をやめたのでツイート数が増えています。2020年は学校に通っていたのでツイート数が増え、2021年にまた起業したのでツイートが減っています。
2017年は子会社社長として働いていたのでツイート数が特に減っています。親会社の人に仕事中にTwitterはしてはいけないと教えてもらったからです。
いいねの多かったツイートを10個表形式で表示してください

自分の考えたバズ狙いのツイートより育児ネタが多いのは少し悔しいです。
メンションが多い順に10人表形式で

1社目を一緒に創業したDominion525でした。やはり。
(ここから本番)この人物がどんな人なのか推定させる

ツイートからどれぐらいのことがわかるでしょうか
性別

男性で正解です。
male_pronouns = ['僕', '俺', 'ボク', 'オレ'] female_pronouns = ['私', 'あたし', 'ウチ', 'あたい', 'アタシ']
上記のようなワードの出現頻度をカウントしました。
年齢

40代ということで正解でした。こんな雑な方法でという感じがしますが偶然っぽい感じもあります。
era_names = ['昭和', '平成', '令和'] decades = ['60年代', '70年代', '80年代', '90年代', '2000年代', '2010年代', '2020年代']
こんなワードの出現頻度をカウントしています。
職業

IT系ということで正解でした。
job_keywords = {
'IT': ['プログラミング', 'データ分析', 'AI', '機械学習', 'ソフトウェア', 'コーディング', 'データサイエンス', 'ウェブ開発'],
'Media': ['ライティング', '編集', 'ジャーナリズム', '報道', 'メディア', '出版'],
'Education': ['教育', '教師', '学校', '学生', '学習', '講師', '教授', '大学'],
'Business': ['ビジネス', '経営', 'マーケティング', '経済', '販売', 'マネジメント'],
'Health': ['医療', '医師', '看護', '健康', '病院', '診療']
}
こんなキーワードで分類しようとしています。ちょっと網羅できている感じはないですね。
居住地

東京と出てしまいました。愛知が正解なのですが私が居住地に言及するときは名古屋ということの方が多いでしょうからそれが影響していそうです。
支持政党

政党名で推定するということをしています。私は政治のことは発言しないので推定できませんでしたが、きちんと解析すれば傾向は分析できそうです。
もし私がAという政党のSNS担当なら、まずAという政党に考えの近い政党Bの支持者を探し、B党のフェイクニュース広告を提示するともにA党のイメージアップ広告を流すでしょう。
また、今回の結果からは少なくとも私が政治に関心が薄いということが推定できているとも言えます。そういう人の方が強固な支持政党が決まっている人よりは広告を表示させた場合に気持ちを変えてくれる可能性が高そうです。
この人は選挙の投票に行くか?

普段選挙に行く人か行かない人かというのは重要な情報です。行かない人は政治に関心が薄いので浮動票として逆に狙い目だからです。
家族構成

これは公開してないのでモザイクをしますが結構当たっていて怖いです。
自動車メーカーは?

これももっとちゃんとやれば推測可能そうです。特に画像を解析すれば簡単かもしれません。その人が乗ってる自動車というのはその人の思想や年収や家族構成を表現しています。
Googleストリートビューの車の傾向から支持政党を推測するなんて話もありました。 MIT Tech Review: ストリート・ビューと深層学習で、街ごとの政党支持を判別可能に
年収

これ以上は進めませんでしたが推定できそうです。
オカルトを信じるか?

これがバレると詐欺のためのリストに掲載されそうです
まとめ

かなりのことが推定されました。私は仕事でもTwitterを使っていましたし、実名でやっていたのでそれなりにプライベートを晒していたのでというのはあるかもしれません。
しかし、これだけのことが単純なキーワードの出現頻度だけで推定されたのが怖いです。これにちゃんと高度な分析や、画像の解析も加えればマーケティング活動や政治工作には十分すぎることが推定できてしまいそうです。
今回は1人について分析しただけでしたがこれらの手順をまとめて適用すれば
- 新婚でもうすぐ家を買いそうな人
- 婚活を始めたばかりで年収の高い人
- 最近加齢で特定のコンプレックスがある人
- 子供が生まれたばかりで学資ローンを組みそうで収入の低い人
- 我が政党と考えが近く、フェイクニュースの効果がありそうな人
- 陰謀論に弱くお金にルーズな人
と言ったことをパーっとリストにできそうです
恐ろしいのはこういったデータに加えてSNS運営側はもっと多くの情報を持っており、広告主はピンポイントで広告やフェイクニュースを流すことができるということです。誰と繋がっているか、何をいいねしたかなどを加えることも分析に役に立ちます。悪い政治家や、詐欺師、悪徳企業でなくてもこれを利用したい人は多いでしょう。SNSの利用というのはこういうことなのだと改めて肝に銘じるべきです。
冗談半分で始めた分析でしたが、思いがけない体験になりました。